
この記事では、データベース設計の基本的な内容や作業について簡単にまとめていきます。
データベーステーブルの構成
設計について触れる前に、データベーステーブルの構成についてまとめておきます。
テーブルは以下のように、行(=レコード)と列(=属性)で構成されます。
ユーザー(users)テーブル:
| user_id | name | email_address | department_id |
|---|---|---|---|
| 1 | Aさん | a-sanno-mail@example.com | 1 |
| 2 | Bさん | b-sanno-mail@example.com | 1 |
| 3 | Cさん | c-sanno-mail@example.com | 3 |
部署(departments)テーブル:
| department_id | name |
|---|---|
| 1 | X部署 |
| 2 | Y部署 |
| 3 | Z部署 |
主キーと外部キー
テーブルでは、主キー / 外部キー という仕組みが使用されます。
主キー(PK)
主キー(PK : Primary Key)は、テーブルに必ず一つは必要なキーです。
レコードを一意に識別する役割があるため、主キーとする属性は原則、重複が禁止となります。
上記の例では、user_id や department_id がこれに該当します
外部キー(FK)
外部キー(FK : Foreign Key)は別テーブルを参照(イメージとしては接続)するためのキーです。
設定することで参照制約を持たせ、「存在しないデータの紐づけ」を防止できます。
(主キーのように必須ではありません)
上記の例では、ユーザー(users)テーブルの department_id がこれに該当します
→usersテーブルのdepertment_id には参照制約が付き、存在しない部署IDの登録を防止。
制約
テーブルには、データを取り扱いやすくするため、以下のような制約を設定できます。
| 制約 | 概要 | 備考 |
|---|---|---|
| NOT NULL制約 | 登録データの空欄(NULL)を禁止 | 主キー列には必ず設定 |
| 一意制約 | 登録データの重複を禁止 | idやメールアドレスで設定 |
| CHECK制約 | 登録データの値を制限(if文のイメージ) | 〇以上/以下や〇~〇内などを設定可能 |
| 参照制約 | FK参照先テーブルの持つ値以外の登録を禁止 | FK(外部キー)設定時の付与される制約 |
3層スキーマ
データベースは、影響範囲を分離する目的から、以下三層の構造(スキーマ)で設計されます。
- 外部スキーマ:ユーザー(アプリ)が認識するDB構造。表示されている部分。
- 概念スキーマ:開発者の認識するDB構造。”テーブル”の定義を行う部分。
- 内部スキーマ:ハードウェア要素を含む、具体的なデータの保存方法を定義。
論理設計
三層スキーマにおける概念スキーマ部分の設計。基本的に物理設計より前に行います。
ポイントとして、物理的制約は内部スキーマ(物理設計)が担当のため、ここでは考慮外になります。
要はテーブルとその関係性の設計担当で、以下の手順で進めていきます。
- エンティティ(実体)の抽出
- 属性の定義
- 正規化
- ER図の作成
エンティティの抽出
「実体」とも言われる、開発するシステムを構成するデータ要素のようなものです。
最終的にはテーブルになるデータまとまりであり、例えば以下のようなものになります。
例:ToDoアプリ → 「ユーザー」「タスク」
雰囲気としては「〇〇情報」と言ってみて違和感がなければとりあえず抽出してOKだと思います。
属性の定義
抽出したエンティティの持つデータ(属性:attribute)を決めていきます。
例の場合、以下のようになります。
| 抽出したエンティティ | 属性 |
|---|---|
| ユーザー | ・ユーザーID (PK) ・名前 ・メールアドレス |
| タスク | ・タスクID (PK) ・担当ユーザーID (FK → ユーザー.ユーザーID) ・優先度 ・タイトル ・状態(未完了/完了) ・期限 |
※この段階での主キーや外部キーの設定は大雑把で大丈夫です。
正規化
データテーブルの整理作業です。1~3段階のチェックリストのようなもので、段階的にデータテーブルの冗長性をなくし、データを扱いやすくします。
| 正規化 | 概要 | 注目ポイント |
|---|---|---|
| 第一正規化 | 「1つのセルには一つの値のみが入っていること」の確認 →複数ある値は別レコードとして追加 | 所属やタグなど、 複数の割り当てがある情報 |
| 第二正規化 | (複合主キーを持つテーブルで、) 「部分関数従属が含まれていないこと」の確認 →テーブルの分割と外部キー(参照制約)の設定 | 主キーとなっている属性と、 それに対応する各属性の関係 |
| 第三正規化 | 「推移的関数従属が含まれていないこと」の確認 | 主キー以外の各種ID系など、 一意性のあるの情報 |
複雑なことをやっているように見えますが、要は以下ルールによるデータ分離です。
- 「1つのセルには1つのデータ」
- 「ある属性から別の属性が特定できるなら、それを主キーにしてテーブルを分割」
また、重要な点として、正規化によるテーブル分割とパフォーマンスはトレードオフの関係にあります。(具体的な調整は主に物理設計の段階で実施)
→正規化はあくまで基準のため、正規化自体が目的にならないようにご注意ください。
 hiramame
hiramame個人的にはテーブル数を増やし過ぎたくないため、第一・第二正規化まではとりあえず実施し、第三正規化の対象がある場合は分離ではなく一旦テーブル構造を再検討で解消を試みることが多いです
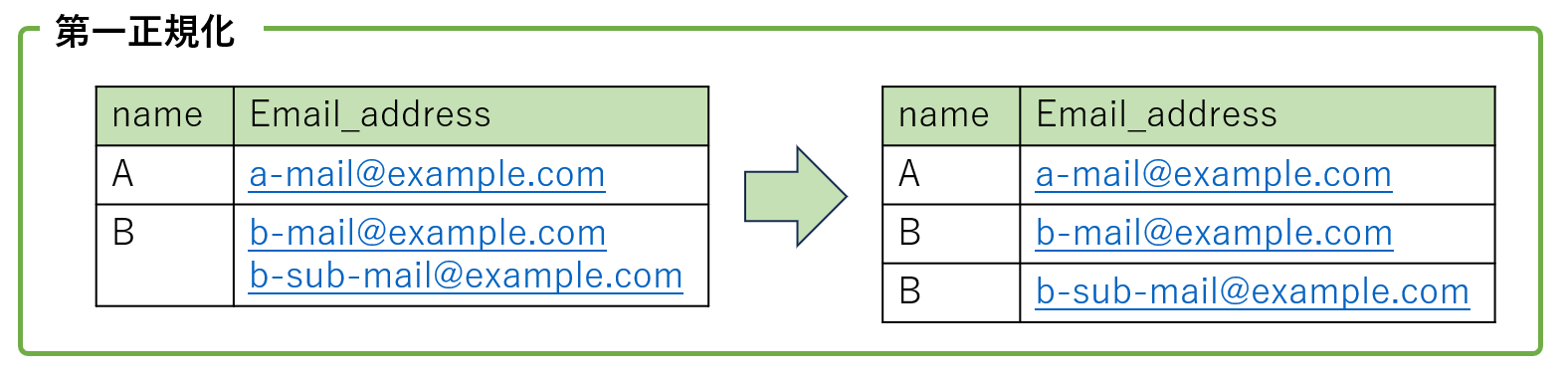
第一正規化の例
第一正規化は「テーブル」の体裁を保つための最も基本的な整理です。
「各セルの情報が単一になっていること」を意識して、以下の例ように正規化できます。
関数従属の種類と第二/第三正規化
以下に、第二/第三正規化で判断基準となる、関数従属についてまとめておきます。
関数従属は、「ある属性の値によって、別の属性の値が特定できる」状態です。
例えば、学籍番号や商品IDなどから学生の氏名や商品名などが特定できる、というものです。
関数従属には以下の種類があります。
- 完全関数従属 :複合主キーのすべての列によってのみ特定が可能な状態
- 部分完全従属 :複合主キーの一部の列によって特定が可能な状態
- 推移的関数従属:主キーに対して、間接的に特定が可能な項目がある状態
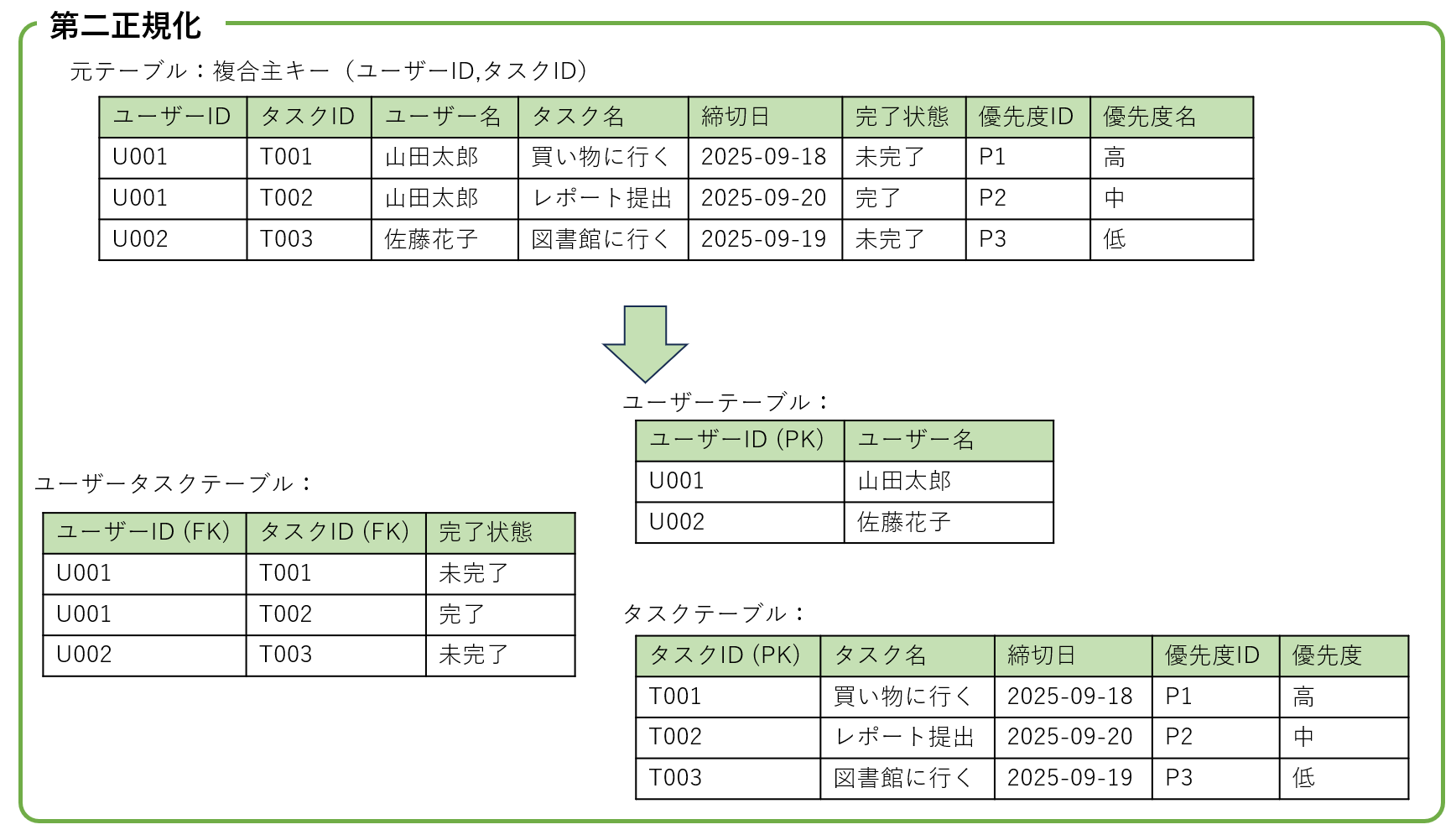
以下、複合主キー (ユーザーID, タスクID) を持つ冗長なテーブルを例に説明します。
| ユーザーID | タスクID | ユーザー名 | タスク名 | 締切日 | 完了状態 | 優先度ID | 優先度名 |
|---|---|---|---|---|---|---|---|
| U001 | T001 | 山田太郎 | 買い物に行く | 2025-09-18 | 未完了 | P1 | 高 |
| U001 | T002 | 山田太郎 | レポート提出 | 2025-09-20 | 完了 | P2 | 中 |
| U002 | T003 | 佐藤花子 | 図書館に行く | 2025-09-19 | 未完了 | P3 | 低 |
この場合、各従属関係と正規化対応は以下のようになります。
- 完全関数従属は、
(ユーザーID, タスクID) → 完了状態
→対応不要 - 部分完全従属は、
ユーザーID → ユーザー名とタスクID → (タスク名, 締切日, 優先度ID, 優先度名)
→第二正規化で解消 - 推移的関数従属は、
(ユーザーID, タスクID) → 優先度名
→第三正規化で解消
流れとしては、第二正規化で、ユーザータスク、ユーザー , タスク と、主キーにかかわる部分を分離。
第三正規化で、タスク テーブル内で冗長となる、優先度ID -> 優先度 を分離し、
最終的に、ユーザータスク、ユーザー , タスク と優先度 という4つのテーブルに正規化します。
今回の例で第三正規化まで実施した場合は、以下のようになります。
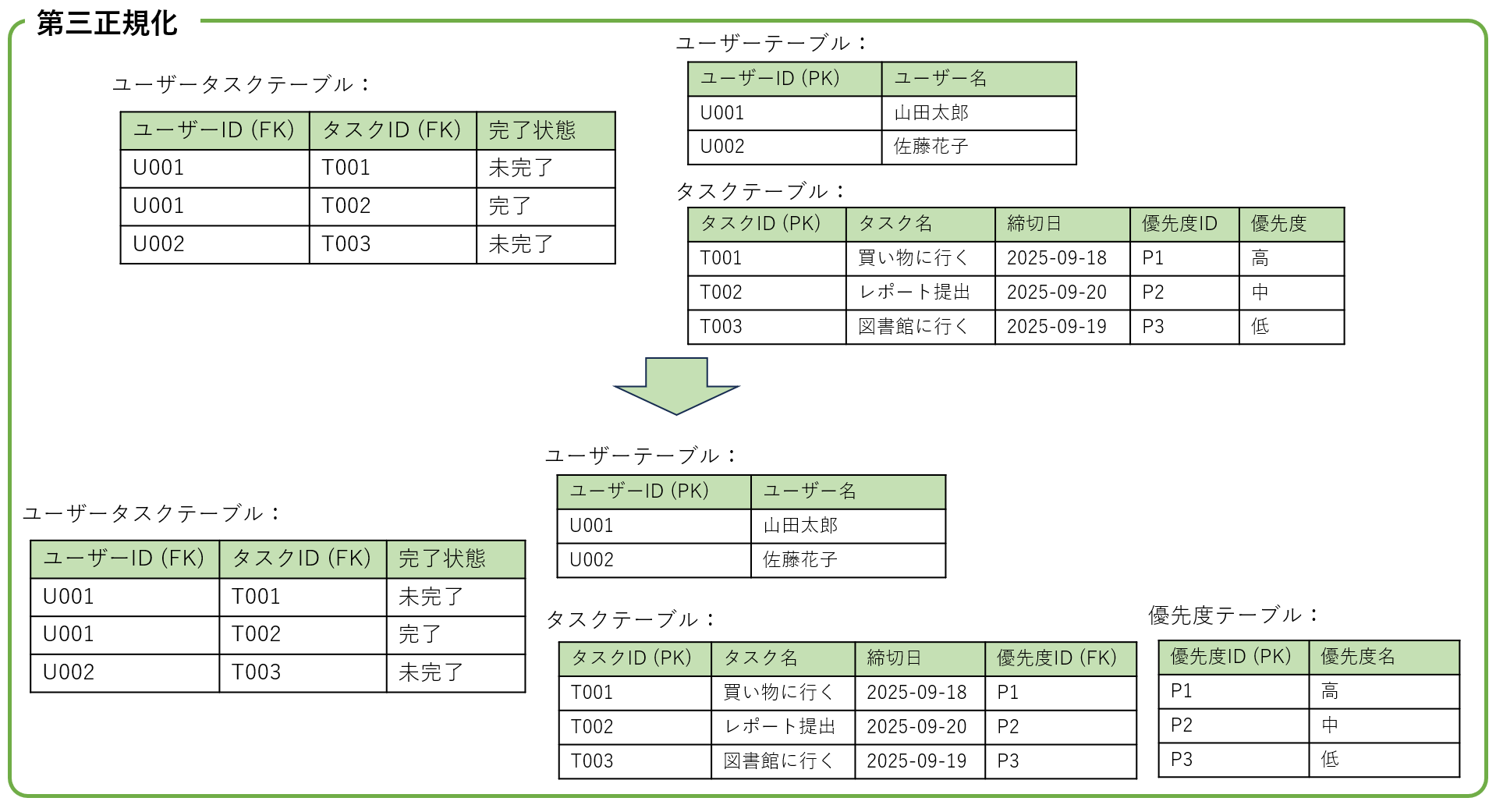
(参考)正規化後のテーブルまとめ
users_tasks テーブル(PK: (ユーザーID, タスクID))
| user_id (FK) | task_id (FK) | status |
|---|---|---|
| U001 | T001 | 未完了 |
| U001 | T002 | 完了 |
| U002 | T003 | 未完了 |
users テーブル:
| user_id (PK) | user_name |
|---|---|
| U001 | 山田太郎 |
| U002 | 佐藤花子 |
tasks テーブル:
| task_id (PK) | task_name | deadline | priority_id (FK) |
|---|---|---|---|
| T001 | 買い物に行く | 2025-09-18 | P1 |
| T002 | レポート提出 | 2025-09-20 | P2 |
| T003 | 図書館に行く | 2025-09-19 | P3 |
priorities テーブル
| priority_id (PK) | priority_name |
|---|---|
| P1 | 高 |
| P2 | 中 |
| P3 | 低 |
ER図の作成
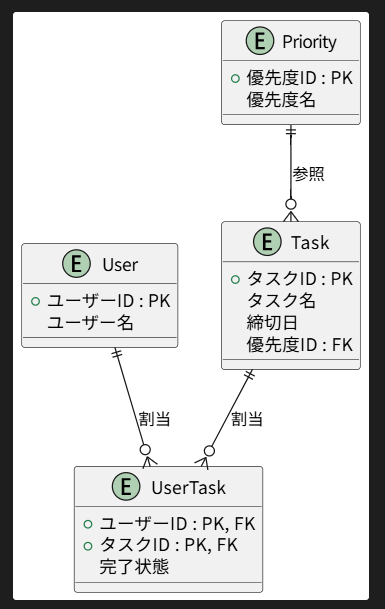
ER図は、各エンティティ間の関係( 1対1 , 1対多 , 多対多 )を図でまとまるものです。
正規化の内容も踏まえて、主キーや複合キーもここで整理します。
以下は、PlantUMLを使用して記述・作成した例です。
- User
- 主キー:
ユーザーID - ユーザー名を保持
- 主キー:
- Task
- 主キー:
タスクID - 優先度IDを外部キーとして保持
- 主キー:
- UserTask
- 複合主キー:
(ユーザーID, タスクID) - 完了状態を保持
- User・Task とそれぞれ外部キー制約あり
- 複合主キー:
- Priority
- 主キー:
優先度ID - タスクの優先度名を保持
- Task が参照することで推移的関数従属を解消
- 主キー:
PlantUML コード
@startuml db_test
/' User(ユーザー)エンティティ:
ユーザー情報を保持する基本テーブル。 '/
entity "User" as User {
+ユーザーID : PK /' 主キー(ユーザー識別) '/
ユーザー名 /' ユーザーの表示名 '/
}
/' Task(タスク)エンティティ:
タスクの内容や締切などを保持するテーブル。 '/
entity "Task" as Task {
+タスクID : PK /' 主キー(タスク識別) '/
タスク名 /' タスクの名称 '/
締切日 /' タスクの期限 '/
優先度ID : FK /' Priority への外部キー '/
}
/' UserTask(ユーザーとタスクの多対多を表す中間テーブル) '/
entity "UserTask" as UserTask {
+ユーザーID : PK, FK /' User への外部キー+複合主キー '/
+タスクID : PK, FK /' Task への外部キー+複合主キー '/
完了状態 /' 完了フラグや状態を示す '/
}
/' Priority(優先度管理テーブル) '/
entity "Priority" as Priority {
+優先度ID : PK /' 主キー '/
優先度名 /' 優先度名(高、中、低など) '/
}
/' User と UserTask:
1ユーザーは複数のタスク割り当てを持つ。 '/
User ||--o{ UserTask : "割当"
/' Task と UserTask:
1つのタスクは複数のユーザーに割り当て可能。 '/
Task ||--o{ UserTask : "割当"
/' Priority と Task:
1つの優先度に複数のタスクが属する。 '/
Priority ||--o{ Task : "参照"
@enduml物理設計
三層スキーマにおける内部スキーマ部分の設計で、主にDBMS上での運用方法(保存・検索・更新方法とその効率化)を定めていきます。
物理設計は「性能・運用を考慮した現実的な落とし込み」で、論理設計をそのまま実装するのではなく、データ量や利用シナリオを見据えて 型・インデックス・非正規化・パーティション・運用方法 を細かく決めることがポイントです。
物理設計で行う主な作業内容は以下の通りです。
| 作業内容 | 具体例 |
|---|---|
| テーブル定義の具体化 | ・データ型の決定(INT, VARCHAR, DATE など) ・NULL制約・DEFAULT値・CHECK制約の設定 ・外部キー制約の有無の決定(パフォーマンスや運用方針に応じて調整) |
| インデックス設計 | ・主キー・外部キーに対するインデックス ・検索条件・ソート条件に多用される列へのインデックス ・インデックスの種類(B-tree, Hash, フルテキストなど) |
| 正規化と非正規化のバランス調整 | 論理設計で正規化されたものをそのまま実装すると、JOINが増えてパフォーマンス低下する場合がある → 必要に応じて 非正規化(冗長データの保持) を検討 |
| パーティション設計 | ・大規模データ向けに、テーブルを日付やIDごとに分割して格納 ・アクセス頻度が高いデータと低いデータを分けて管理 |
| ストレージ・ファイル設計 | ・表領域、データファイル、ログファイルの配置 ・I/O分散による性能向上 |
| 運用に関する設計 | ・バックアップ・リストア戦略 ・レプリケーション、クラスタリング構成 ・データ量見積もりと将来の増加に備えた拡張性 |
- テーブル定義書(DDL定義)
- インデックス定義
- ビュー定義
- ストレージ割り当て設計書
- バックアップ/リカバリ設計
ToDoアプリにおける物理設計の例
例として ToDoアプリ を題材にしながら、物理設計での各作業について以下にまとめます。
(0) 論理設計(前提)
論理設計では、以下のようなテーブルを設計したとします。
- User(ユーザー)
user_id(PK),name,email- Task(タスク)
task_id(PK),user_id(FK),title,description,due_date,status- Category(カテゴリー)
category_id(PK),name- TaskCategory(タスクとカテゴリーの中間テーブル)
task_id(FK),category_id(FK), (PK: 複合主キー)
(1) テーブル定義の具体化
論理設計で抽象的だった部分を、DBMS上の具体的な型や制約に落とし込みます。
例:Task テーブル
| 論理項目 | 物理型 | 制約 |
|---|---|---|
| task_id | BIGINT | PK, AUTO_INCREMENT |
| user_id | BIGINT | FK (User.user_id) |
| title | VARCHAR(255) | NOT NULL |
| description | TEXT | NULL |
| due_date | DATE | NULL |
| status | CHAR(1) | NOT NULL, DEFAULT ‘0’ (0:未完了, 1:完了) |
ポイント:
VARCHARの長さは業務要件に応じて設定TEXT型はインデックスが効きにくいため、検索用途があるなら分割を検討statusのような区分値はENUMを使うか、小さな整数(TINYINT/CHAR)で表現
(2) インデックス設計
検索・結合・ソートの頻度を考慮して設計します。
Task.task_id→ 主キーインデックスTask.user_id→ 外部キー制約+検索用途があるためインデックスTask.due_date→ 期限順に並べ替える用途にインデックスを付与Task.status→ 「未完了タスク一覧」の取得に多用される場合はインデックス候補
ポイント:
- インデックスは検索を速くするが、INSERT/UPDATE/DELETE では更新コストが増える
- 頻度分析(どの検索が多いか)を前提に決定する
(3) 正規化と非正規化のバランス調整
論理設計では正規化されているため、JOIN が増える可能性があります。
例えば、タスク一覧を表示する時に ユーザー名・カテゴリ名も表示 するなら:
SELECT t.task_id, t.title, u.name, c.name
FROM Task t
JOIN User u ON t.user_id = u.user_id
JOIN TaskCategory tc ON t.task_id = tc.task_id
JOIN Category c ON tc.category_id = c.category_id;JOIN が多いとパフォーマンスが落ちるため、以下の工夫が考えられます。
- 冗長カラムの保持
Taskにcategory_name_cacheを持たせる - マテリアライズドビューの利用
頻出クエリ結果を事前に保持する
ポイント:更新性能より検索性能を重視する画面では非正規化が有効
(4) パーティション設計
大規模利用を想定する場合、タスク数は膨大になります。
例:期限日 (due_date) ごとにパーティション分割
Task_2025_Q1Task_2025_Q2- …
効果:
- 過去データへのアクセスは少ないので、検索対象を限定して高速化
- バックアップやアーカイブ運用が容易
(5) ストレージ・ファイル設計
- テーブルスペース分離
大きなテーブル(Task)と小さなマスタ(User, Category)を別の表領域に配置し、I/O負荷を分散 - ログファイルとデータファイルの分離
書き込み性能向上・障害復旧効率化
MySQLの場合:
InnoDBテーブルを複数ファイルに分ける (innodb_file_per_table)- SSD にホットデータ、HDD にアーカイブデータを配置
(6) 運用に関する設計
- バックアップ戦略
- 毎日フルバックアップ+数時間ごとの増分バックアップ
- 期限切れタスクをアーカイブしてバックアップ容量を削減
- リカバリ設計
- トランザクションログを利用して障害発生時に直前まで復旧
- 拡張性確保
- ユーザー数が増えた場合に備えてシャーディング(UserID単位でDBを分割)を検討
物理設計のアウトプット(ToDoアプリ例)
- テーブル定義書(DDL)
CREATE TABLE Task (
task_id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_id BIGINT NOT NULL,
title VARCHAR(255) NOT NULL,
description TEXT,
due_date DATE,
status CHAR(1) NOT NULL DEFAULT '0',
INDEX idx_task_user (user_id),
INDEX idx_task_due (due_date),
INDEX idx_task_status (status),
FOREIGN KEY (user_id) REFERENCES User(user_id)
);- インデックス設計書
idx_task_user: ユーザー別タスク一覧の検索を高速化idx_task_due: 期限順ソートで利用idx_task_status: 未完了タスク検索で利用
3. ストレージ設計書
Taskテーブルを専用テーブルスペースに配置- バイナリログを別ディスクに保存
4. 運用設計書
- バックアップポリシー、リストア手順
- パーティション管理ルール
